Durgesh KalwarI am a researcher at TCS Research, working under the supervision of Harshad Khadilkar, where I am working on developing a new methodology for directed exploration using General Value Functions in Reinforcement Learning and its application to supply chain management. Lately, I've also been working on Safe RL and adaptive consensus-based distributed training of NN for a static graph topology. Before joining TCS Research lab, I did my M.Tech. in Machine Learning and Computing from Indian Institute of Space Science and Technology. My thesis was on Safe Exploration in Reinforcement Learning and it mainly focused on safe sequential optimization in switching environments. I pursued my undergraduate in Electrical Engineering from S. V. National Institute of Technology, India. My thesis was on State Estimation and Control Experiments on Quadrotor, in which I designed and implemented software on an STM32 microcontroller, which incorporated a Kalman filter and enhanced PID control algorithm. Email / CV / GitHub / Google Scholar / LinkedIn / Transcript |

|
ResearchI'm interested in reinforcement learning, machine learning, optimization, distributed learning and robotics. |
|
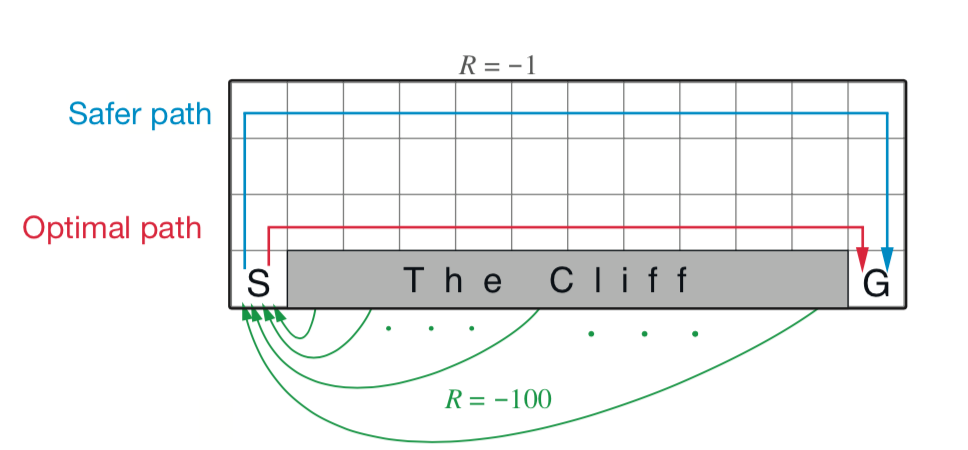
Guiding Offline Reinforcement Learning using Safety ExpertRicha Verma Durgesh Kalwar, Harshad Khadilkar, Balaraman Ravindran Accepted in CODS-COMAD conference, 2024 paper / In this paper, we proposed an approach called GORL (Guided Offline-RL) that leverages a safety expert to guide the offline RL agent in choosing safe actions in uncertain states. This approach can be applied to existing offline RL algorithms and has been shown to outperform current methods in terms of safety without sacrificing performance. |
|
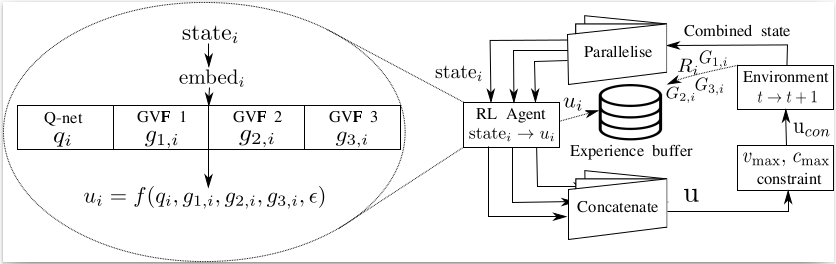
Using General Value Functions to Learn Domain-Backed Inventory Management PoliciesDurgesh Kalwar, Omkar Shelke, Harshad Khadilkar arxiv, 2023 paper / In this paper, we utilize GVFs to learn domain-backed inventory management policies. GVFs are trained on domain-critical characteristics such as prediction of stock-out probability and wastage quantity. Using this domain expertise for more effective exploration, we train an RL agent to compute the inventory replenishment quantities for a large range of products (up to 6000), which share aggregate constraints such as the total weight/volume per delivery. Additionally, we showed that the GVF predictions can be used to provide additional domain-backed insights into the decisions proposed by the RL agent. |
|
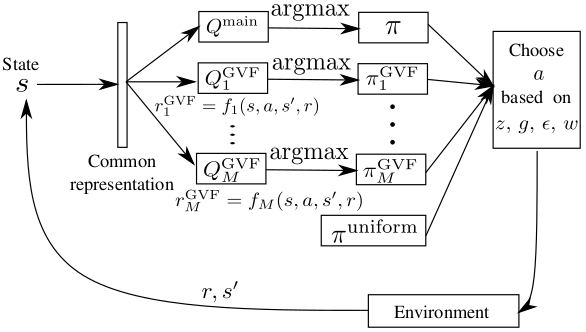
Follow your Nose: Using General Value Functions for Directed Exploration in Reinforcement LearningDurgesh Kalwar, Omkar Shelke, Somjit Nath, Hardik Meisheri, Harshad Khadilkar International Conference on Autonomous Agents and Multiagent Systems (AAMAS), 2023 paper / poster / In this paper, we proposed a General Value functions (GVFs) based exploration strategy to effectively explore in a directed manner in hard exploration tasks. |
|
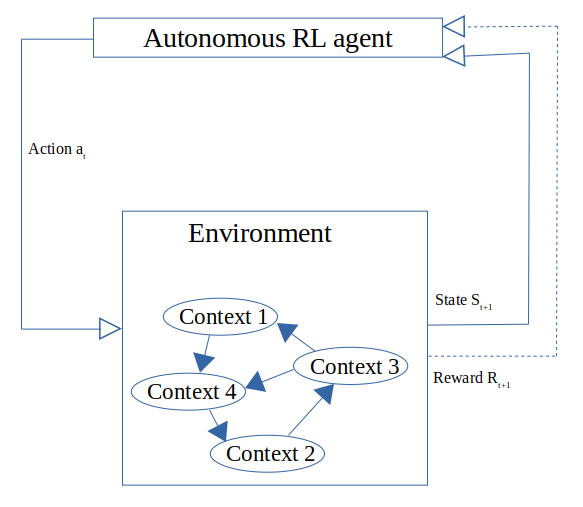
Safe Sequential Optimization in Switching EnvironmentsDurgesh Kalwar, Vineeth Bala Sukumaran National Conference on Communications (NCC), 2021 paper / In this paper, we considered the problem of designing a sequential decision-making agent to maximize an unknown time-varying function that switches with time. The agent is also constrained to make safe decisions with a high probability during the exploration phase. For this safe sequential optimization problem, we proposed an algorithm called Adaptive-SafeOpt, which incorporates Bayesian optimization and change point detection. |
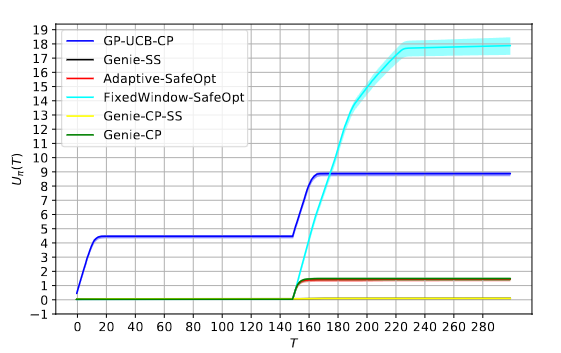
|
Safe Exploration in Reinforcement LearningDurgesh Kalwar Master's Thesis, 2021 paper / |
|
Design and source code from Jon Barron's website |